


Talk to Your Files: Build an Internal Chatbot with N8N, Pinecone, OpenAI, and Telegram
Instant answers from your files

N8N is easily the coolest tool I have discovered in the past 6 months. Using a simple drag and drop interface, it enables you to setup sophisticated workflows with AI agents. While it does have a bit of a learning curve and require some technical chops, I have found it far easier to use than Langchain or even CrewAI, which I covered here.
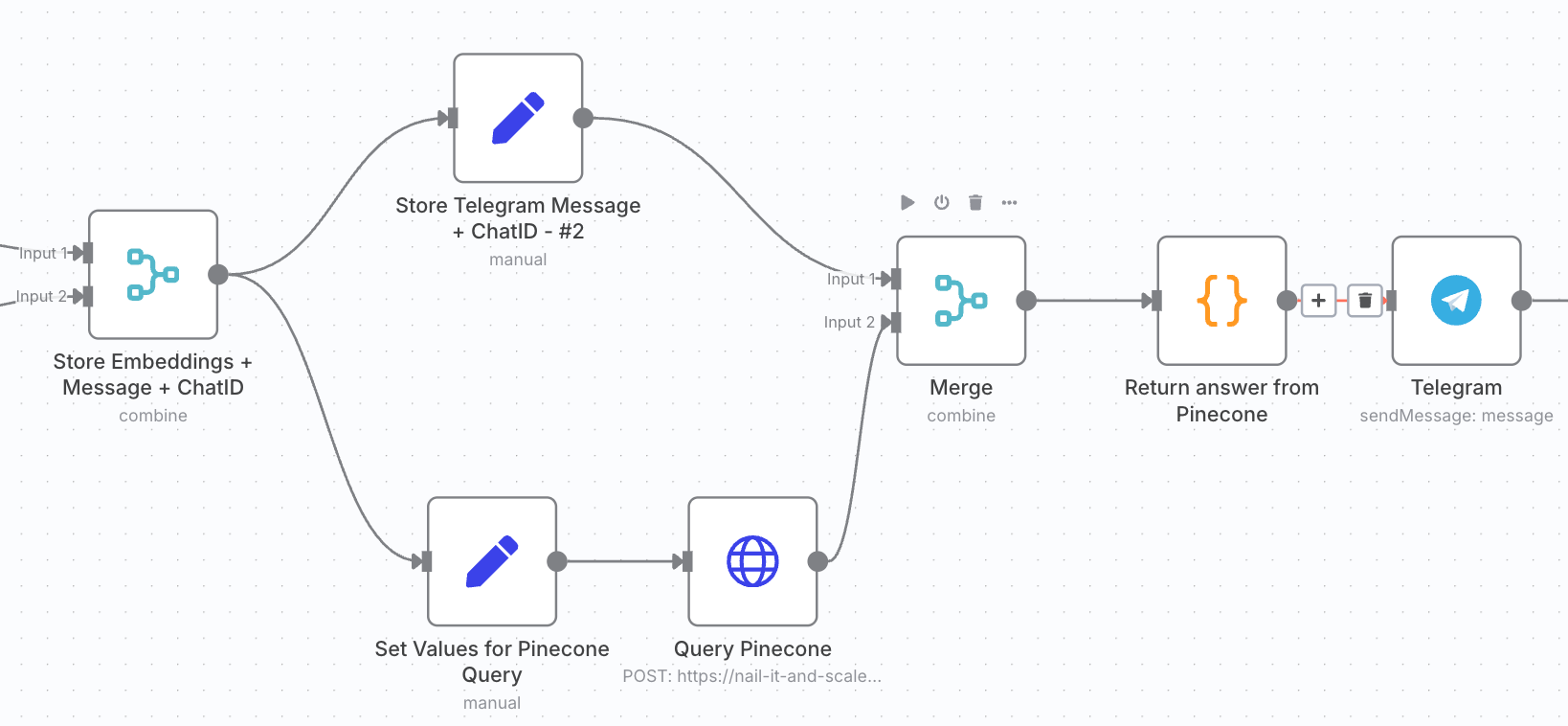
In today’s article, I will be doing a walkthrough of an N8N workflow I created that enables you to chat with your internal files using a Telegram chatbot. In practical terms, let’s say you have an internal company knowledge base of 100 files. With this workflow, you could ping your chatbot, it will identify the file most likely to return a relevant answer, and then answer you based on the file content.
A few things to mention before diving in:
#1 - While there are other creators far more experienced in AI automation (Nate Herk is one of my favorites), my hope is to bring some of these ideas to new circles where they are not as well-known.
#2 - There is a ton of hype in the AI space, and I like to try things myself (e.g. as I did in my AI coding article) and provide an unfiltered analysis of how well something actually works and how hard it is to implement.
#3 - To use N8N effectively, you will need some basic knowledge of coding and API requests. I gloss over a few technical details in this article for the sake of speed and readability.
Anyone not interested in reading the full article can find the summary here. Also, below is a video of me walking through the end solution.
Pinecone, Semantic Search, and Retrieval Augmented Generation (RAG)
Most people are familiar with OpenAI, the parent company of ChatGPT. The messaging app Telegram, known for its speed, privacy features, and flexibility, is also relatively well-known. But, Pinecone, the vector database that makes this whole project possible, is less well known outside of AI circles. To understand the purpose of Pinecone, it is necessary to first explain two additional concepts: Semantic Search and Retrieval Augmented Generation (known as “RAG”).
Retrieval Augmented Generation (RAG): You know how ChatGPT and other AI models can answer questions? Sometimes, they use what they know (built-in training), but that knowledge might be outdated. RAG is a way to make AI models smarter by helping them “look things up” from outside sources before answering. For example, feeding ChatGPT context from your company’s internal documents.
Semantic Search: When doing a query to feed data into AI models, it’s important that the system understands what you mean as opposed to just searching for exact words. Imagine you’re looking for a book about “how to cook healthy meals,” but instead of typing that exact phrase, you ask:
“What are some tips for quick and nutritious dinners?”
Semantic Search might show you results about “healthy cooking,” “fast recipes,” or “nutritious meals,” even if those exact words weren’t used in your question.
Pinecone: Pinecone is a vector database that enables you to store data for the purpose of semantic search. The data you pass to Pinecone is first embedded and then stored as vectors (i.e. random codes of numbers), so that it can be searched semantically. Think of Pinecone as a giant, organized filing cabinet - but instead of storing words alphabetically, it stores the meaning of things. And it can instantly find the most relevant answers to any question you ask.
Step 1: Create accounts and setup API credentials in N8N
To kick-off this project, you will need to sign-up for accounts with the following providers (these are all free to sign-up for):
-Pinecone
-OpenAI
-Telegram
-Google Cloud
You will then need to generate API keys for the following services (ask ChatGPT if you have any confusion about how to do this):
-Pinecone
-OpenAI
-Telegram
-Google Drive (set this up in Google Cloud)
-Google Sheets (set this up in Google Cloud)
Finally, you will need to setup these credentials in the “Credentials” section of N8N. If you have made API requests in the past, and are familiar with API keys, these steps should be relatively straightforward.

Step 2: Setup your Pinecone vector database
When I first heard of Pinecone and vector databases, I assumed it was incredibly complex and beyond my capabilities. After diving in myself, I discovered that it is actually very straightforward, and pretty intuitive if you have a technical background (it’s actually far easier than setting up a SQL database).
You simply need to login to Pinecone, hit the “Create Index” button, and select your features, including the database “Name”, “Cloud”, “Region”, and “Embedding Model”. The ones I selected were:
Name: nail-it-and-scale-it-rag
Cloud: AWS
Region: us-east-1
Embedding model: text-embedding-3-small

Step 3: Convert files to PDFs and store them in a Google Drive folder
This one was pretty straightforward. I chose to use my Substack articles as my knowledge base, so I exported them from Substack and then used this service to convert the html files to pdf files. Next, I just added the PDF files to a Google Drive folder and set the sharing permissions to “Anyone Can View”.

Step 4: Store the filenames and file IDs in variables
Now, we finally dive into N8N, and setup a few nodes with the purpose of storing our filenames and file IDs in variables for later use. The “Get Folder ID” is a necessary precursor to “Get File IDs”, and then the data, including filename, is stored in variables in the “Set Name” node. The “Flatten Array” node is used for some data cleanup before things are stored.

Step 5: Extract each file’s text
Next, using N8N’s built-in “Get Content” and “PDF Extract” nodes, we will be extracting the full text from each file. Once extracted, the text is cleaned up (i.e. removing random characters, extra spaces, etc.) using some code I got from ChatGPT. The “Merge” mode is what captures the end output, and is needed here to make sure both the cleaned up text and filename are available for use later in the flow.

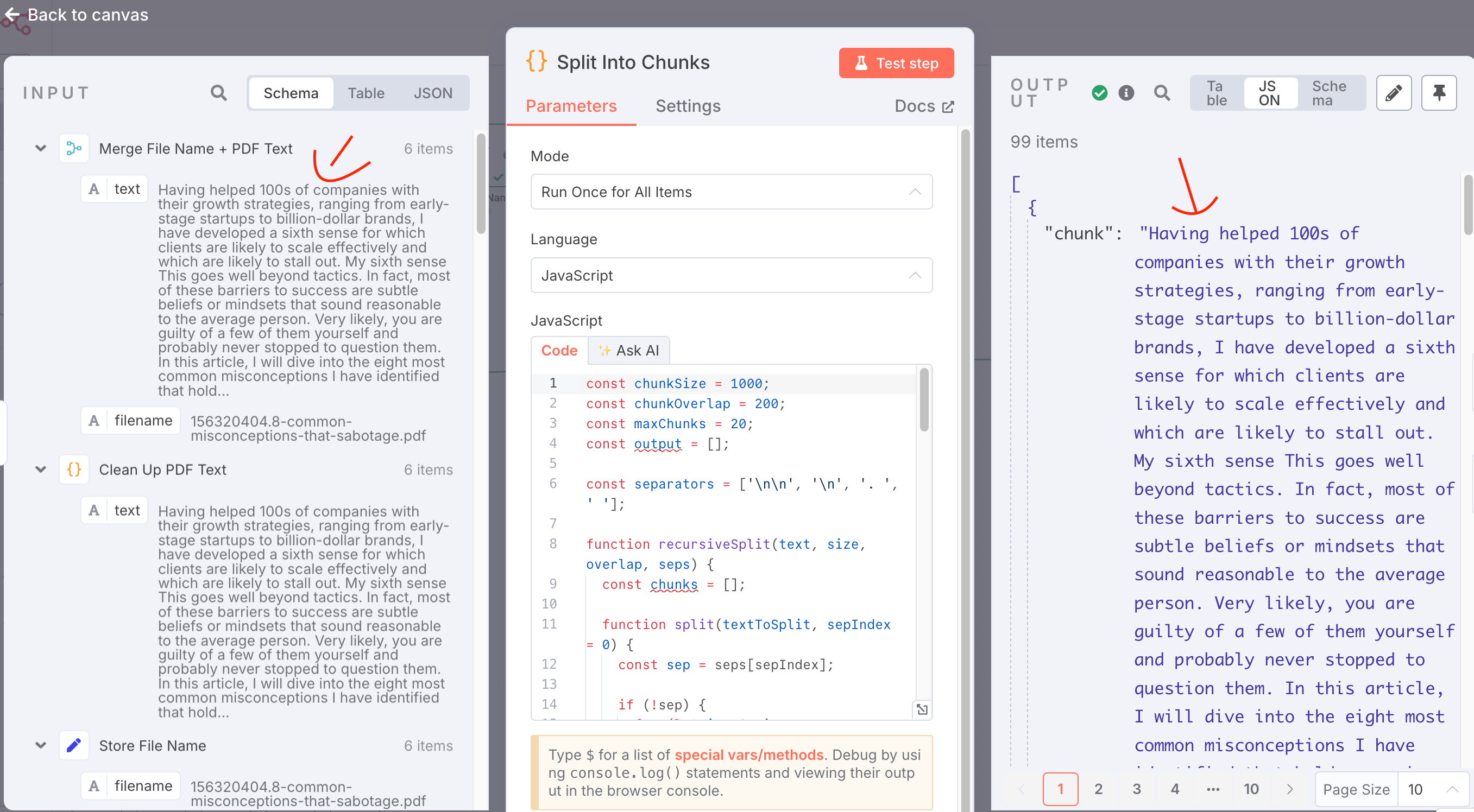
Step 6: Break text into chunks
We are ultimately going to be feeding the PDF data to the OpenAI API to analyze it and create “Question and Answer” summaries based on the text. The only problem: these are large PDFs and if we attempt to feed the whole file in at once, we will run into API rate limits. The solution is to first ‘Chunk’ the data (i.e. break it into bite-sized pieces) so that the API will accept it. I did this using a “Code Node” with some code provided by ChatGPT.
Step 7: Create Q&A from chunk content
Just as we can’t feed entire PDFs to the ChatGPT API all at once, we also can’t have AI models read entire PDF documents every time there is a new user query. This would be far too slow and use up too much memory.
Instead, we need to generate a question and answer block from each chunk that our chatbot can reference later. I did this by feeding each chunk to the OpenAI API with the following prompt.

Step 8: Generate Embeddings using Q&A text block
When storing data in Pinecone, there are two components:
#1 Embeddings - Embeddings are technically a random array of numbers, but represent how your data gets stored and indexed in Pinecone. When Pinecone is later queried, the embedded data is what gets searched.
#2 - Metadata - The data that gets returned once the query is completed.
I generated embeddings by making a call to the OpenAI API and feeding it the question and answer pairs. The screenshot below shows how I did this along with some sample outputs.

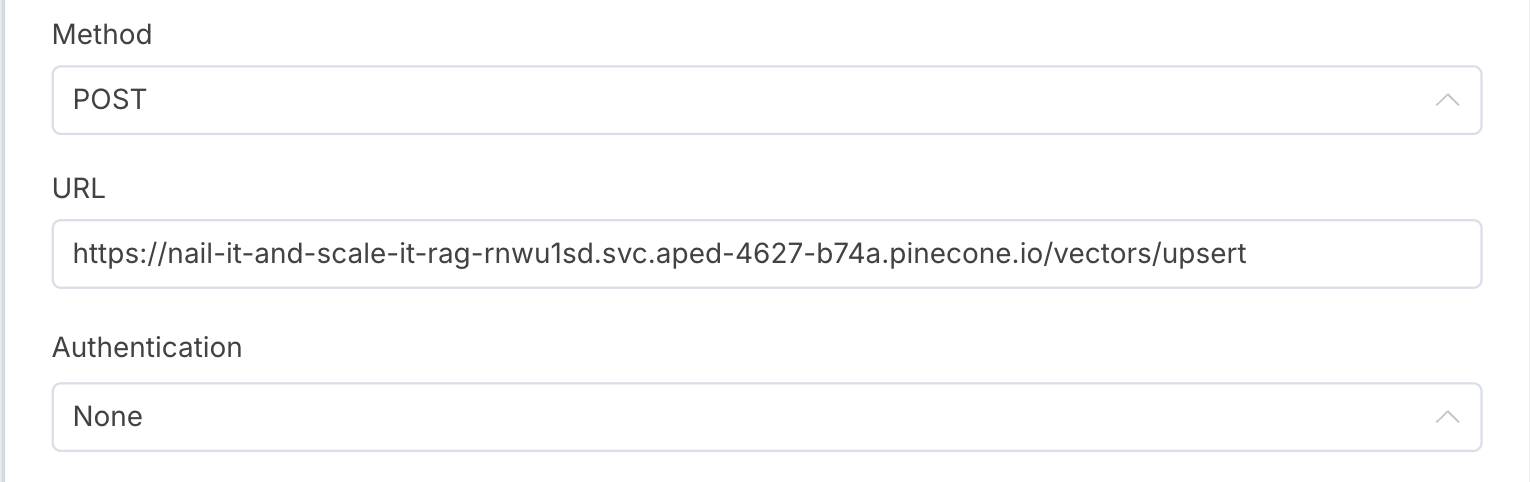
Step 9: Store data in Pinecone
Once I have my embeddings ready, and all my data stored in metadata, I am ready to pass my data into Pinecone. I used a POST request to send data to the Pinecone API (as shown below).
I also passed the following variables in my request body:

In plain English, what is being passed in is the following:
Id: Pinecone requires an ID to be passed in with any request. I used a random number generator to create mine.
Chunk: The chunk of text that we sliced off from the original PDF.
Filename: The filename of the original PDF.
Answer: The answer to return if there is a match with the query.
Values: The embeddings we are passing in (based off the Q&A block).
Step 10: Setup your Telegram bot
Now that the data is in Pinecone, the next step is to setup our Telegram bot, so we can query the dataset. Assuming you have already created a Telegram account, you can create your own bot in Telegram by doing the following:
#1 - Open Telegram and search for BotFather (official bot by Telegram).
#2 - Start the chat and click /start.
#3 - Send the command /newbot.
#4 - Follow the prompts:
-Give your bot a name (e.g., "My Weather Bot").
-Give it a username that ends in bot (e.g. myweatherbot).
-BotFather will respond with a token – this is your bot’s API key. Save it.
Finally, setup a new Workflow in N8N that has a “Telegram Trigger”, and insert your API key into that node.

Step 11: Embed your Telegram message
Next, if we want to query Pinecone, which stores data via embeddings, we will need to query the system using embeddings as well. This is a nearly identical process to step 8, except that the parameters I pass in are the embedding model to use and the Telegram message (as shown below).

Step 12: Query Pinecone and get an answer back
Now, all that is left is to send a request in Telegram and to get an answer back. An example of this output can be found below.

Conclusion
With a bit of technical know-how and some patience upfront, N8N allows you to create a highly functional AI chatbot capable of intelligently querying your internal documents and returning meaningful answers - right from a messaging app. While the process requires understanding APIs, vector databases, and chunking logic, the payoff is a powerful, customizable system that would have required an entire engineering team just a few years ago. As AI tools continue to mature, platforms like N8N are making sophisticated automation more accessible than ever. If you’re even slightly technical and curious about AI agents, this is a great project to dive into.
If you liked this content, please click the <3 button on Substack so I know which content to double down on.
TLDR Summary
This article explores how to use N8N, a drag-and-drop automation tool, to create a sophisticated AI chatbot that can query your internal documents via Telegram. By integrating tools like Pinecone for semantic search and OpenAI for generating embeddings, the chatbot can intelligently pull answers from documents stored in Google Drive. The guide walks through each step, from setting up the necessary accounts and APIs to creating the workflow in N8N and querying data through Telegram.
Key Steps and Insights
Introduction to N8N
N8N offers a simple drag-and-drop interface for creating complex workflows.
The article demonstrates how to use N8N to build an AI-powered chatbot that can access internal company knowledge.
Key Technologies
Pinecone: A vector database enabling semantic search and data storage in embeddings.
Retrieval Augmented Generation (RAG): Enhances AI models by enabling them to retrieve external data before answering queries.
Semantic Search: Helps the AI model understand intent beyond exact keyword matches.
Setting Up the Workflow
Create accounts with necessary providers (Pinecone, OpenAI, Telegram, Google Cloud).
Set up API credentials in N8N for smooth integration.
Build a Pinecone vector database for storing data in semantic embeddings.
Document Handling and Chunking
Convert documents to PDFs, store them in Google Drive, and extract text with N8N’s “PDF Extract” node.
Break large documents into smaller chunks for processing by OpenAI and avoid API rate limits.
Embedding Generation and Storage
Use OpenAI to generate embeddings for Q&A blocks from document content.
Store embeddings and metadata in Pinecone for fast, relevant search results.
Setting Up Telegram Bot for Interaction
Create a Telegram bot using BotFather and connect it to N8N via API keys.
Embed Telegram messages with query parameters to interact with Pinecone.
Querying and Retrieving Answers
Use embeddings to query Pinecone from Telegram and return meaningful answers based on document content.
Conclusion
By combining N8N with tools like Pinecone and OpenAI, you can build a powerful, customizable AI chatbot capable of querying internal documents with ease. The process requires some technical knowledge, but the result is a sophisticated, efficient system that would have previously required significant development resources. N8N’s drag-and-drop interface makes these advanced workflows more accessible, offering a great entry point for those curious about AI agents and automation.